
因子分析をこれまで何度か試してきたのですが、要はどういう傾向があるのかがわかる、影響を与える因子を見つけることができるというものだったんですけど、そもそもデータにたいして、属性のパラメータがついてんだから、何か仲間ごとに分類できないのかね?と思ったら、世の中にはクラスタ分析ってものがあるらしいです。しかも、例のごとくそれがPython で簡単にできるらしいので、試してみます。いちいち無駄にエラーばっかり吐き出す言語の分際で結構便利なことができますよね。あの蛇言語。

fclusterを使ってクラスタ分類を実施する
毎回恒例ですが、あの時に使ったデータをベースに実施したいと思います。
外向性、社交性、積極性、知性、信頼性、素直さの属性を持った生徒に対して因子分析をしたあのデータです。今度はメンバーごとに属性的に班ができたりするんでしょうか?
以下コード
import pandas as pd
import numpy as np
#これがクラスタ分析に使うライブラリ
from scipy.cluster.hierarchy import linkage, fcluster,dendrogram
import matplotlib.pyplot as plt
data=pd.read_csv("./syougakusei.csv")
#一旦データをみてみる
dataさて、データをみてるとこんな感じ
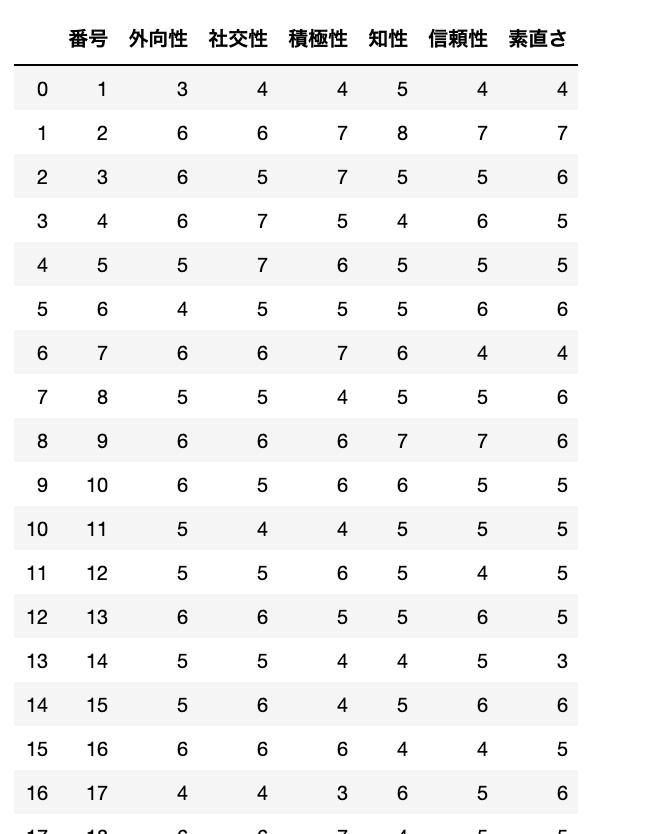
ちょっとややこしいですが、インデックスの番号は0から始まっていて、このデータ、生徒を番号で呼んでいて、1から始まってるという、なかなかわかりづらい状況です。なので、元のインデックスは破棄して、この番号をインデックスに変更しておきます。
あとあと、データのずれとかに気づきづらくなるのは危険です。
data.set_index("番号",inplace=True)
#念の為確認
data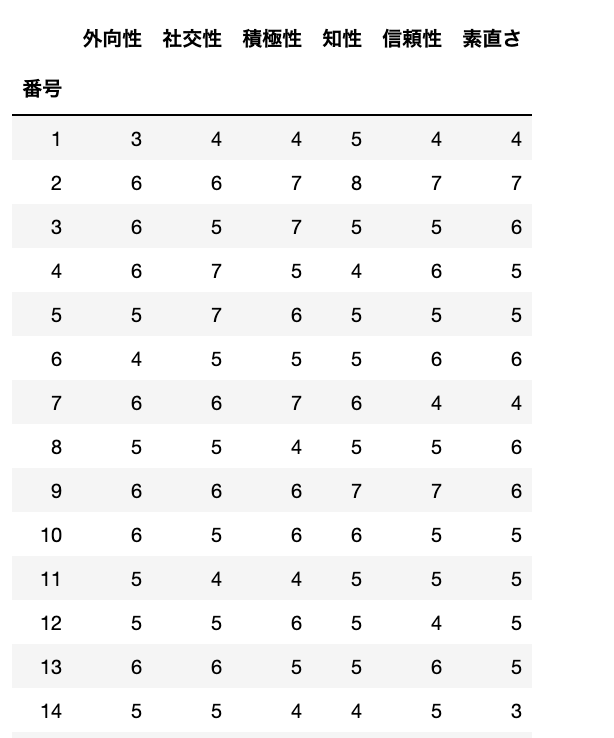
うん、きっちり元のインデックスはなくなってくれました。これで読み違えることがなくなりました。
断言できます!番号は生徒の番号のことで、インデックス番号のことではありません!
さて、ではウォード法によるクラスタ分析を実施します
#methodで方法を指定。
w = linkage(data, method='ward')
#一旦中身を確認
w
さて、中身を確認します

はい、よくわからんが、ちゃんと出てます。で、これはどういう過程で分類されていくかを確認する必要がありますね。
なぜなら、分類わけなんて、最大で要素数まで分類(もはや分類になってないけど)できるんだから、
何個に分類するのか?というのを考える必要があるので、目で確認します
dendrogram(w, leaf_font_size=10,color_threshold=7,above_threshold_color='black',labels=data.index)
plt.show()

ふーむ。。。
だいたい、Y軸方向に3メモリぐらいの粒度がいいんじゃないんでしょうかね。。。好みですが。
となると、5個に分類したほうがよさそうですね。
#クラスタリングしたものを、5個で分類する
clust_data = fcluster(w, 5, criterion='maxclust')
#columnsに指定がないと、0とか数値がカラム名になってわかりづらいので、
#クラスタの番号ってことで、clust_noに名前をしてみました。
clust_data_fm=pd.DataFrame(clust_data,columns=["clust_no"])
#重要!ややこしい話ですが、ユーザー番号は1から始まってますが、このclust_data_fmは、
#list型をDataFrameにしてるので、0番からスタートしてるので、
#元データと1つインデックスがずれることになるので、+1をして、同じにしておきます
clust_data_fm.index=clust_data_fm.index+1
#元データと結合します
result=pd.concat([data,clust_data_fm],axis=1)
#データをclust_noで並べてみてみましょう
result.sort_values("clust_no")

うん、途中でみた、ドラゴンボールの天下一武道会トーナメント表みたいな図と一致してますね。
無事にクラスタリングが完了しました。






